BAB I
PENDAHULUAN
1. Latar Belakang
Beberapa saat yang lalu, banyak orang ramai memakai AI untuk membuat gambar dengan style animasi, termasuk tren gambar ala Studio Ghibli yang sempat viral di medsos. Bagi banyak orang, hal ini terlihat seru karena AI bisa mengubah foto biasa menjadi aaaagambar dengan style Ghibli dengan mudah dan cepat. Namun, di balik tren yang menarik itu, muncul pertanyaan yang lebih serius: AI ini sebenarnya belajar dari mana sampai bisa menghasilkan gambar yang terasa mirip dengan gaya karya manusia?
Sebenarnya, kemampuan AI untuk menghasilkan gambar atau tulisan yang meyakinkan tidak muncul begitu saja. AI dilatih menggunakan data dalam jumlah sangat besar yang diambil dari internet, seperti gambar, tulisan, ilustrasi, dan berbagai karya lain yang tersedia secara publik. Masalahnya, tidak semua karya yang ada di internet otomatis boleh dipakai untuk melatih AI, apalagi jika digunakan tanpa izin yang jelas dari pemiliknya, di sinilah muncul konflik etika dan hukum. Oleh karena itu, pembahasan dalam makalah ini menekankan bagaimana AI mengambil data dari internet untuk training dan mengapa hal tersebut menimbulkan masalah.
2. Rumusan Masalah
Berdasarkan latar belakang, makalah ini disusun untuk menganalisis penggunaan data internet dalam pelatihan Generative AI, mengidentifikasi nilai yang diuntungkan dan dikorbankan, menilai pihak yang paling diuntungkan dan paling berisiko dirugikan, menentukan dimensi moral Laudon yang paling dominan, serta merumuskan kerangka keputusan etis dan rekomendasi kebijakan yang lebih adil dan manusiawi.
BAB II
PEMBAHASAN
1. Sistem dan Teknologi yang Digunakan
Sistem yang dibahas dalam makalah ini adalah Generative AI. AI dilatih dari data yang tersebar di internet. OpenAI sendiri menjelaskan bahwa pemilik situs dapat memblokir datanya agar tidak dipakai untuk melatih AI. Hal itu menunjukkan bahwa data web memang dipakai untuk training AI, tetapi beban penolakan justru ada pada pemilik situs.
2. Nilai nilai yang diuntungkan
Nilai yang diuntungkan dari sistem ini adalah efisiensi, kecepatan, dan kemudahan akses. Dengan data yang besar, AI bisa belajar lebih cepat dan menyempurnakan hasilnya. Selain itu, pengguna juga bisa membuat sesuatu dengan cepat tanpa harus memiliki skill tinggi. Dari segi ekonomi, hal ini menguntungkan karena pengguna tidak perlu membayar jasa mahal dan menunggu lama
3. Nilai nilai yang dikorbankan
Nilai yang dikorbankan dalam sistem ini adalah hak cipta, kontrol kreator atas karya, dan privasi. Karya yang diunggah ke internet belum tentu dibuat untuk melatih AI. Karena itu, meskipun data bersifat publik, penggunaannya untuk training tetap menimbulkan masalah etis jika dilakukan tanpa izin yang jelas.
4. Pihak yang paling diuntungkan
Pihak yang paling diuntungkan dalam sistem ini adalah perusahaan pengembang AI, karena mereka melatih model, lalu menjual layanan tersebut ke publik atau bisnis tampa mengeluarkan effort yang berlebih. Mereka hanya mengumpulkan data yang ada di publik lalu mengolahnya. Pengguna juga mendapat manfaat, namun tidak sebesar perusahaan.
5. Pihak yang paling dirugikan
Pihak yang paling dirugikan disini adalah kreator asli, pemilik situs, dan semua orang yang datanya digunakan untuk training AI tampa dia ketahui. Hal itu tentunya sangat merugikan disisi lain mereka tidak mendapatkan apa apa dari datanya yang digunakan ,dan mereka juga terancam kehilangan pekerjaan karena AI bisa melakukan hal yang menjadi keahlianya. Disisi lain perusahaan AI sangatlah untung karena bisa mendapat data ,dan digunakan untuk menarik pengguna baru.
Contoh dari kasus ini adalah dimana kita bisa membuat gambar dengan style Ghibli dengan mengeprompt di ChatGPT. Dan hal tersebut viral diseluruh dunia sehingga banyak orang yang menggunakan fitur tersebut. Hal itu membuat kreator Ghibli yaitu hayao miyazaki marah karena ia merasa tidak mengizinkan karyanya digunakan untuk mentraining AI. Tentu saja yang diutungkan dari hal ini adalah perusahaan AI karena banyak pengguna yang menggunakan AInya. Namun kreator ghibli dirugikan karena ia tidak dapat apa apa ,dan sekarang semua orang bisa mengikuti style gambarnya tanpa belajar.
6. Dimensi Moral Laudon yang Paling Dominan
Untuk Dari lima dimensi moral Laudon, dimensi yang paling dominan adalah Property Rights and Obligations. Inti persoalannya adalah siapa yang berhak menentukan penggunaan karya atau data di internet. Apakah semua karya yang bisa diakses publik otomatis boleh dipakai untuk training AI.
Selain itu, dimensi Privacy and Freedom juga muncul, karena data publik kadang masih membawa unsur pribadi yang tidak bisa diproses seenaknya. Masalah berikutnya adalah dimensi Accountability and Control. Dalam sistem AI perusahaan bisa mengatakan datanya berasal dari web publik, sementara pengguna hanya merasa memakai alat yang sudah jadi. Akibatnya, tidak jelas siapa yang seharusnya bertanggung jawab ketika karya orang lain dipakai tanpa izin atau ketika data pribadi ikut masuk ke proses training.
7. Ethical Decision Framework
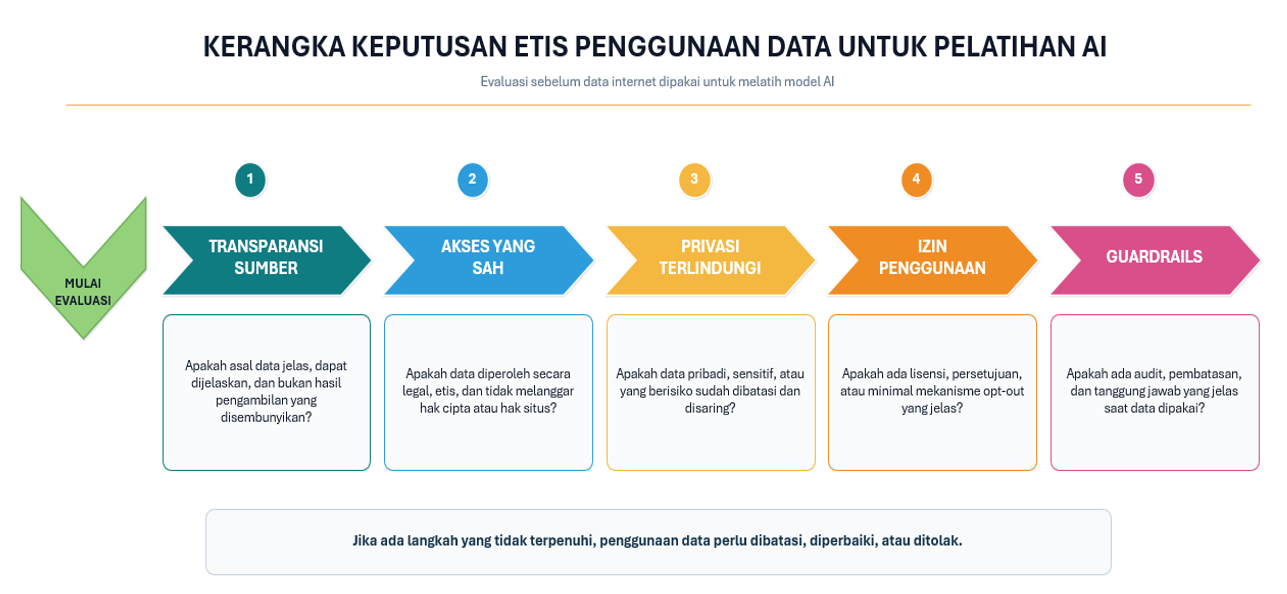
Kerangka keputusan etis ini terdiri dari lima langkah utama.
- Kejelasan Sumber Data
Langkah pertama adalah menilai apakah sumber data pelatihan jelas asal-usulnya. Data yang dipakai seharusnya berasal dari sumber yang dapat dijelaskan, bukan sekadar diambil dari internet tanpa penjelasan yang pasti.
- Legalitas dan Kelayakan Akses
Langkah kedua adalah menilai apakah data diperoleh dengan cara yang sah dan etis. Walaupun suatu karya dapat diakses publik, hal itu tidak otomatis berarti karya tersebut bebas dipakai untuk melatih AI komersial.
- Perlindungan Privasi
Langkah ketiga adalah memastikan bahwa data yang digunakan tidak mengandung unsur pribadi atau sensitif yang dapat merugikan seseorang. Jika data memiliki risiko privasi yang tinggi, maka data tersebut seharusnya dibatasi atau tidak dipakai sama sekali
- Persetujuan atau Mekanisme Penolakan
Langkah keempat adalah melihat apakah pemilik data atau pemilik situs memiliki ruang untuk memberi izin atau menolak penggunaan datanya. Sistem yang etis seharusnya tidak membebankan seluruh tanggung jawab perlindungan kepada pemilik data saja.
- Pengamanan dan Akuntabilitas
Langkah terakhir adalah memastikan adanya pengamanan, audit, dan pihak yang bertanggung jawab. Jika terjadi pelanggaran hak cipta atau penyalahgunaan data, harus jelas siapa yang bertanggung jawab, bukan justru saling lempar kesalahan antara perusahaan, penyusun dataset, dan pengguna.
hasil penilaian dapat dibagi menjadi tiga kategori jika terpehuni:
- 5/5 langkah→ relatif etis untuk digunakan
- 3-4/5 langkah → perlu pembatasan atau perbaikan
- 0-2/5 langkah → tidak layak digunakan
BAB III
KESIMPULAN
A. Kesimpulan
Tren gambar ala Ghibli memang membuat isu AI terasa dekat dan mudah dilihat publik, tetapi masalah yang lebih penting sebenarnya ada pada cara AI dilatih. Generative AI berkembang dari data internet dalam jumlah besar, dan di dalam data itu terdapat karya berhak cipta serta data yang kadang masih menyentuh privasi. Karena itu, audit etika AI tidak boleh hanya melihat hasil akhirnya, tetapi juga harus menilai dari mana data diambil, apakah ada izin, dan siapa yang menanggung risikonya. Menurut saya, AI akan lebih adil jika dibangun dengan data yang lebih transparan, lebih menghormati hak kreator, dan lebih jelas batasnya terhadap data pribadi.
B. Rekomendasi Kebijakan dan Desain Sistem
Berdasarkan analisis tersebut, ada tiga rekomendasi utama.
- Perusahaan AI harus lebih transparan tentang kategori data yang dipakai untuk training.
- Karya berhak cipta sebaiknya dipakai dengan bentuk persetujuan yang lebih jelas, bukan hanya mengandalkan anggapan bahwa data publik bebas digunakan.
- Mekanisme penolakan sebuah karya digunakan AI harus dibuat lebih sederhana dan mudah dipahami